RAID5 Data Recovery
[ Problems of RAID5 Arrays |
Structure of a RAID5 Array |
Recovery Tools |
Download ]
This page is about recovery of data from crashed RAID5 arrays. You
need a basic understanding of how RAID5 arrays work to
make the best use of this page. I don't give any warantee for the
correctness of the information
or programs below. If that makes you nervous, you should
pay money to have your data salvaged by a professional disaster
recovery company.
Before attempting to do data recovery yourself take a copy of the disks
in the array and work on the copies, otherwise you risk making a
bad situation much, much worse. If you have hardware RAID, you
should attach the disks to a normal SCSI or IDE controller so
that you can access all of the disks.
If you have working backups, don't bother with this page at all,
unless you are in it for the challenge.
It's very tempting to assume that a RAID5 array is rock solid
reliable, and in certain ways, it is – it can cope with a single
disk failure, a common cause of data loss. On the other hand, a failing
drive controller can cause the entire array to fail. Data on an
array is also
susceptible to damage from bad software (not forgetting
the firmware
on a hardware RAID controller), bad RAM and human error.
RAID is NOT a substitute for backups.
Unfortunately, it's easier to get the time and funding for
providing on-line storage than it is for the hardware to backup
that data.
Latent disk errors
- A disk block can have data: this data can read in the normal way.
- A disk block can have known errors: the operating system knows that
the block is unreadable and that it needs to be reconstructed
from blocks on the other disks.
- A disk block can have unknown errors: these are latent errors that
render the block unreadable that the OS hasn't discovered yet.
It is the latter category that tends to cause difficulties.
Suppose that you have a latent disk error on a part of a disk that is
either unused by the filesystem or is a parity block for an area
that rarely changes. During normal operation, the existence of this error
won't cause any difficulties. If a second disk error causes different
disk to be marked as bad, that disk's data will be reconstructed
onto a spare disk. The reconstruction will read every disk block on
the active disks, so it will detect the latent disk error,
marking that disk off-line too. There are no longer enough active
disks so the entire array fails.
Regular surface scans are essential to detect latent disk errors.
TIP
If you haven't been doing surface scans, your RAID5 array fails and
you don't have a hot spare disk,
you can take the opportunity to take a backup of the data now while
the array is operating in degraded mode.
A latent error in an unused part of the disk shouldn't affect the backup,
however, replacing the faulty disk may crash the array.
Controller Errors
If you are doing RAID with multiple disks on one SCSI or RAID controller,
you can get a bad effect where a controller problem results in a
request to the disk timing out. This looks to the controller like
a problem with the disk device, so the disk is marked off-line.
The faulty controller is still driving the disks, so the same
problem can then happen to another disk. There are then
insufficient disks to drive the array.
If there wasn't really a problem with a disk and you know the
structure of the metadata, you can put the metadata back as it
was when the second drive "failed".
To do this, examine the metadata of all the disks. You should find:
- One metadata block that says no drives have failed.
- One metadata block that says one drive has failed.
- Several metadata blocks that says that the array is incomplete.
Chances are that the timestamps in the matadata are mere seconds apart.
(If they're not, think harder about what went wrong before attempting a
recovery.) The metadata block with one failure is from the second drive
to fail. If you generate new metadata blocks for the other disks
corresponding to this one, you'll end up with a degraded array
with most of your data intact. You should force an fsck after
doing this.
To construct a RAID5 array, first split your data into
blocks of equal length. The size of the blocks will normally be
larger than the block size of the underlying disk, 64K being a
typical figure.

Now arrange these blocks on all but one of the disks rotating through the
disks in sequence. Compute the each bit in the parity blocks (P) in
the remaining disk by
taking the one's complement (xor) of the corresponding bit on other disks.
The one's complement sum over all the disks will be 0. In
the picuture, below, each line corresponds to one disk.
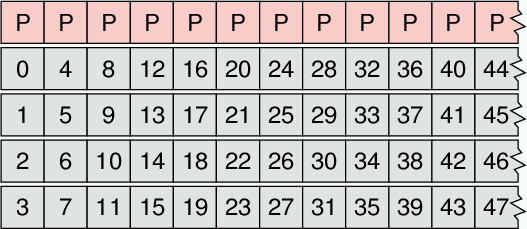
To read a block from the array, calculate its position and
issue a read to the appropriate disk.
To write to a block, you calculate the position of the data block and
the corresponding parity block. You read the data (OD) and
parity (OP) blocks into memory. The new data block (ND)
is written in the normal way. The new parity block is calculated as
NP = OP^ND^OD, where ^ is the one's complement addition
operator (xor). The new partity block is then written to disk.
To read a block from a failed disk, cacluate its position, then
read the corresponding blocks from all the other disks. The data
block will be the one's complement of these blocks.
If you stop here, you have RAID4. This suffers performance
problems during writes - every write requires an update
to the parity disk so that disk is a bottleneck. (Some systems
use RAID4 so that they can grow an array by adding extra disks in
parallel with the others. This is much much harder with RAID5.)
RAID5 avoids the bottleneck by interleaving the parity blocks with the
data blocks.
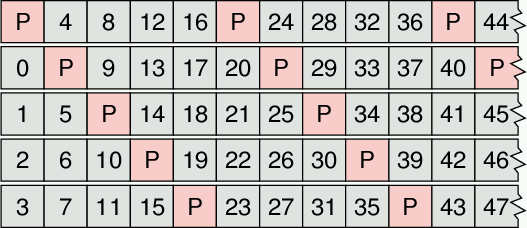
To recover a crashed RAID array you'll
need to know the following parameters:
- Which disks the RAID array is on, and in what order? (Often not
as easy as it sounds!)
- Which disk is the first parity block on? (In the picture, it
starts on the first disk, but this choice is arbitrary. Putting
the first parity block on the last disk makes just as much sense.)
- How large are the blocks? (This is known as the stripe size, which
disambiguates it from disk block size.)
TIP
Look for a data structure on disk that is larger than
stripe size × number of disks. You'll be
able to deduce the stripe size and parity layout by looking for
discontinuities in the data. If you are using LVM1, the PE
allocation table is excellent for this purpose.
When you examing the raw data, don't
be surprised to see apparently real data in the parity blocks.
This is normal if
- the data on all disks is very similar and you have an odd number of disks, or
- all but one data disk contains NULs.
Reconstructions that fail due
to latent errors do so because they operate on whole disks at a
time, marking the entire disk as bad because of one bad sector.
A more pragmatic approach works on single stripes or single disk
blocks at a time, preferring the believed working disks whenever
possible. I don't have a program that automates the recovery process,
but this tool will help you do the recovery manually.
The parity stripe is generated by xoring the data stripes, but
note that the algorithm works the other way too - you can
generate a data stripe by xoring the other data blocks with the
parity stripe. Consequently you can generate a disk block on one disk
from the corresponding block on the other disks without knowing
anything about the stripe length or which disk has the parity stripe.
This program takes a bunch of disks and splices them together
in the same way that a RAID controller would. You can then dd the output
to another disk.
TIP
If you use raidextract to read a filesystem image, you can write the
output to a file and run all the standard filesystem tools (tune2fs, e2fsck) on the file.
Once you've finished, you can the mount the filesystem with mount -o loop.
Example usage:
./raidextract --window 1024 --stripe 16 --rotate 6 \
--start $((0x41C6E79A00)) --length $((4096*1024*64000)) \
--failed 5 /dev/sd[a-g] | ssh othermachine dd of=RecoveredFilesystem
- Window size
- In the example, window is set to 1024K. The program reads this much data
in at a time, so larger values are more efficient, but use more memory.
The program allocates two windows per disk so that it can process
one window while the next is still being read from disk. The example
uses 7 disks so program will allocate 7×2×1024K=14MB.
- Stripe size
- A RAID array splits the data into small units (stripes) that are
placed on each disk in sequence. In the example, the first 16K is
placed on the one disk, then the next 16K is placed on the next
disk, and so on.
- Rotate
- In the example, there are 7 disks; in each set of 7 stripes,
there are 6 data stripes and 1 parity stripe. To avoid one disk
becomine a bottleneck during writes, which disk which holds the
parity stripe changes from one set of stripes to the next.
The program assumes that the parity shifts from sda to sdb to sdc etc.
The rotate parameter sets
the initial position of the parity disks. The position is calculated
for start position 0, so once you've got the correct value, you
don't need to recalculate it to change the start position.
- Start position
- This is the number of bytes to skip in the output stream. The
program calculates the corresponding position in the input streams
and starts producting output. The program does not attempt to
move the output filepointer.
- Length
- This is the number of bytes to output. If the program runs out of data
on one of the input streams, it will tell you how many bytes remained
unwritten.
- Failed
- Normally the program will halt on the first parity error. When
the failed argument is specified, you will be warned about parity errors
but the program will continue regardless, reconstructed from the
remaining disks. Only one disk may be marked as failed.
- Input streams
- In this example, the inputs were disk devices. The program does no
special ioctls, so any input file will do, however, the program
will not read past disk errors.
This program is like the raidextract, except that it only prints what
the program would do. It is useful for identifying which disk holds
the parity at a given point in the output stream.
These programs will not work prior to Linux kernel 2.4.
If you want to run these programs on older systems, or on other Unix
platforms, please read the advice on porting
the programs.
See also
- Tweak
- An efficient hex editor. This is ideal for examining large files
since it doesn't load the file into memory. "
tweak -l" lets
you look at the data without accidentally editing it. At the time
of writing, it cannot cope with files larger than 2GB, so you can't
examine the disk directly. You can work around this limitation by
using dd to copy chunks of the disk into a file.
Peter Benie <peterb@chiark.greenend.org.uk>
Linux
