agedua Unix utility for tracking down wasted disk space
Suppose you're running low on disk space. You need to free some up, by finding something that's a waste of space and deleting it (or moving it to an archive medium). How do you find the right stuff to delete, that saves you the maximum space at the cost of minimum inconvenience?
Unix provides the standard du utility, which scans your
disk and tells you which directories contain the largest amounts of
data. That can help you narrow your search to the things most worth
deleting.
However, that only tells you what's big. What you really want to
know is what's too big. By itself, du won't
let you distinguish between data that's big because you're doing
something that needs it to be big, and data that's big
because you unpacked it once and forgot about it.
Most Unix file systems, in their default mode, helpfully record when a file was last accessed. Not just when it was written or modified, but when it was even read. So if you generated a large amount of data years ago, forgot to clean it up, and have never used it since, then it ought in principle to be possible to use those last-access time stamps to tell the difference between that and a large amount of data you're still using regularly.
agedu is a program which does this. It does basically
the same sort of disk scan as du, but it also records
the last-access times of everything it scans. Then it builds an
index that lets it efficiently generate reports giving a summary of
the results for each subdirectory, and then it produces those
reports on demand.
The best way to explain what agedu does is to show it
in action. Here's a screenshot of an HTML report generated by
agedu after scanning my home directory, and served to
my web browser:
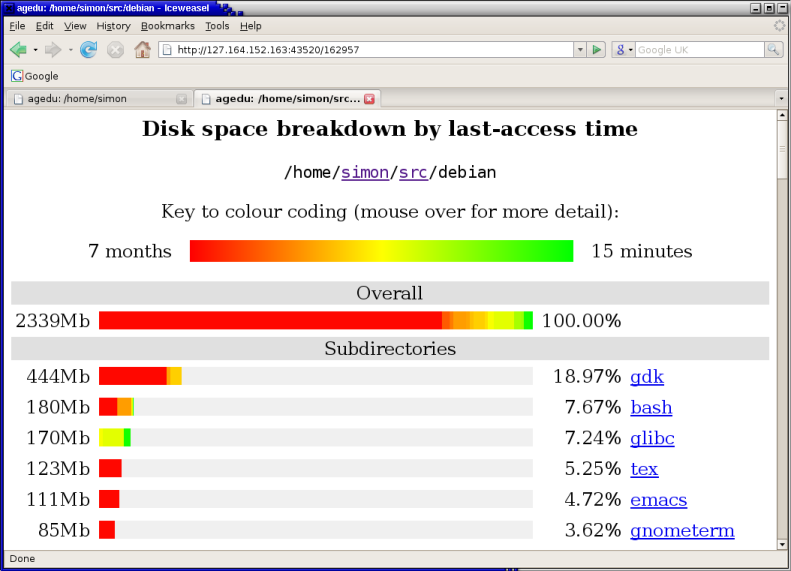
You can see here a big coloured bar representing all the space used
in and below the main directory I'm looking at, and then smaller
bars showing how much of that space is in each subdirectory. Each
coloured bar is drawn in lots of different colours: red represents
data that hasn't been looked at for a long time, green represents
very recently accessed data, and the spectrum through orange and
yellow represents points in between. So I can immediately see that
the gdk subdirectory is not only the largest, but also
that it consists mostly of data I haven't looked at in about seven
months, making it a key candidate for tidying up. By contrast, the
next two directories (bash and glibc)
contain very little wasted space; the one below that,
tex, is a stronger tidying-up candidate than either.
You can see in the screenshot that all the subdirectory names, and some components of the pathname at the top, are hyperlinks. Each one goes to a page centred on a different directory, with that directory's coloured bar expanded to fill the width of the window and all of its subdirectories displayed below it in the same way. Using this, I can browse around my entire home directory until I've identified where the real wastes of space are.
(Of course, I might find a large collection of data which is only
accessed once a year but I do still need to keep it in order to
carry on accessing it once a year. agedu can't
magically find data that's definitely wasted. All it can do
is tell you where are good places to look; it just does that one
notch better than du.)
As well as generating graphical reports like the one shown above,
agedu can also produce text output a bit like
du (but with the additional feature of being able to
show only the disk space used by long-disused files, for any age
cutoff you like).
For complete and excruciating detail, you can read the man page online.
agedu itself does not have a native Windows port
(although one user reported that it at least built in Cygwin).
However, I do have a small Windows utility, which will scan a
Windows system and produce a dump file suitable for loading into
agedu, so if you have a Unix machine available as well
as Windows then you can use agedu that way.
The utility is called
ageduscan.exe.
It produces a log file on standard output, so you will probably want
to run a command like "ageduscan c:\ > scan.dat", or just
"ageduscan > scan.dat" to scan the current
directory. Then copy the output file (scan.dat in these
examples) to a Unix machine where you can run agedu
itself, and load it in using the -L option (see the man page).
agedu
agedu works for me and has had a small amount of beta
testing. I'd be interested to hear from anyone using it on
particularly large amounts of data (say, an order of magnitude or so
larger than a home Linux box).
agedu is distributed under the MIT licence, so it is
free to copy, redistribute, use and reuse. For more details, see the
file called LICENCE in the distribution archive.
A Unix source archive of agedu is available here:
The Windows scan-only utility (see above) is here:
If you want to see the latest state of development, you can check
the development sources out from my git repository:
git clone https://git.tartarus.org/simon/agedu.gitAlternatively, you can browse the repository on the web, here.
Here's a
brief article
describing the data structure used in agedu's index.
If you insist, I won't stop you, but I pronounce it ‘age dee you’.
(Somehow, this program managed to acquire a FAQ before it was even published.)
Please report bugs to anakin@pobox.com.
You might find it helpful to read this article before reporting a bug.
Patches are welcome.