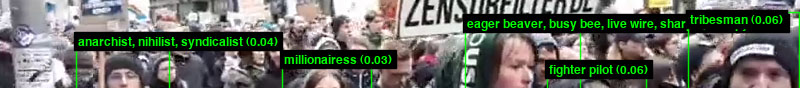
ImageNet Roulette is a provocation
designed to help us see into the ways that humans are classified in
machine learning systems. It uses a neural network trained on the
“Person” categories from the ImageNet dataset which has over 2,500 labels used to classify images of people.
Warning: ImageNet Roulette regularly returns racist, misogynistic and cruel results.
That is because of the underlying data set it is drawing on, which is
ImageNet's 'Person' categories. ImageNet is one of the most influential
training sets in AI. This is a tool designed to show some of the
underlying problems with how AI is classifying people.
Starting Friday, September 27th this application will no longer be available online.


|
computer user: a person who uses computers for work or entertainment or communication or business |

|
lay reader: a layman who is authorized by the bishop to read parts of the service in an Anglican or Episcopal church |

|
appreciator: a person who is fully aware of something and understands it |

|
nonsmoker: a person who does not smoke tobacco |

|
grinner: a person who grins |

|
alliterator: a speaker or writer who makes use of alliteration |

|
psycholinguist: a person (usually a psychologist but sometimes a linguist) who studies the psychological basis of human language |

|
security consultant: an adviser about alarm systems to prevent burglaries |

|
nonsmoker: a person who does not smoke tobacco |

|
grinner: a person who grins |
Starting Friday, September 27th this application will no longer be available online.
ImageNet Roulette was launched earlier this year as part of a broader
project to draw attention to the things that can – and regularly do – go
wrong when artificial intelligence models are trained on problematic
training data.
ImageNet Roulette is trained on the “person” categories from a dataset
called ImageNet (developed at Princeton and Stanford Universities in
2009), one of the most widely used training sets in machine learning
research and development.
We created ImageNet Roulette as a provocation: it acts as a window into
some of the racist, misogynistic, cruel, and simply absurd
categorizations embedded within ImageNet. It lets the training set
“speak for itself,” and in doing so, highlights why classifying people
in this way is unscientific at best, and deeply harmful at worst.
One of the things we struggled with was that if we wanted to show how
problematic these ImageNet classes are, it meant showing all the
offensive and stereotypical terms they contain. We object deeply to
these classifications, yet we think it is important that they are seen,
rather than ignored and tacitly accepted. Our hope was that we could
spark in others the same sense of shock and dismay that we felt as we
studied ImageNet and other benchmark datasets over the last two years.
“Excavating AI” is our investigative article about ImageNet and other problematic training sets. It’s available at https://www.excavating.ai/
A few days ago, the research team responsible for ImageNet announced that after ten years of leaving ImageNet as it was, they will now remove half of the 1.5 million images in the “person” categories. While we may disagree on
the extent to which this kind of “technical debiasing” of training data
will resolve the deep issues at work, we welcome their recognition of
the problem. There needs to be a substantial reassessment of the ethics
of how AI is trained, who it harms, and the inbuilt politics of these
‘ways of seeing.’ So we applaud the ImageNet team for taking the first
step.
ImageNet Roulette has made its point - it has inspired a long-overdue
public conversation about the politics of training data, and we hope it
acts as a call to action for the AI community to contend with the
potential harms of classifying people.
And so as of Friday, September 27th, 2019 we’re taking it off the internet.
It will remain in circulation as a physical art installation, currently
on view at the Fondazione Prada Osservertario in Milan until February
2020.
ImageNet Roulette: An Experiment in Classification
ImageNet is one of the most important and historically significant training sets in artificial intelligence. In the words of its creators, the idea behind ImageNet was to “map out the entire world of objects.” After its initial launch in 2009, ImageNet grew enormous: the development team scraped a collection of many millions of images from the Internet and briefly became the world's largest academic user of Amazon’s Mechanical Turk, using an army of piecemeal workers to sort an average of 50 images each minute into thousands of categories. When it was finished, ImageNet consisted of over 14 million labelled images organized into more than twenty thousand categories.
The underlying structure of ImageNet is based on the semantic structure of Wordnet, a database of word classifications developed at Princeton University in the 1980s.
The ImageNet dataset is typically used for object recognition. But as part of the research for the forthcoming “Excavating AI” project by Trevor Paglen and Kate Crawford, we were interested to see what would happen if we trained an AI model exclusively on its “Person” categories. ImageNet contains 2833 sub-categories under the top-level category “Person.” The sub-category with the most associated pictures is “gal” (with 1664 images) followed by “grandfather” (1662), “dad” (1643), and “chief executive officer” (1614). ImageNet classifies people into a huge range of types including race, nationality, profession, economic status, behavior, character, and even morality.
The result of that experiment is ImageNet Roulette.
ImageNet Roulette uses an open source Caffe deep learning framework trained on the images and labels in the “person” categories (which are currently ‘down for maintenance’). Proper nouns and categories with less than 100 pictures were removed.
When a user uploads a picture, the application first runs a face detector to locate any faces. If it finds any, it sends them to the Caffe model for classification. The application then returns the original images with a bounding box showing the detected face and the label the classifier has assigned to the image. If no faces are detected, the application sends the entire scene to the Caffe model and returns an image with a label in the upper left corner.
ImageNet contains a number of
problematic, offensive and bizarre categories - all drawn from WordNet.
Some use misogynistic or racist terminology. Hence, the results
ImageNet Roulette returns will also draw upon those categories. That is
by design: we want to shed light on what happens when technical systems
are trained on problematic training data. AI classifications of people
are rarely made visible to the people being classified. ImageNet
Roulette provides a glimpse into that process – and to show the ways
things can go wrong.
ImageNet Roulette does not store the photos people upload.
ImageNet Roulette is currently on view at the Fondazione Prada Osservertario museum in Milan as part of the Training Humans exhibition.
A project by Trevor Paglen using images from ImageNet “From Apple to Anomaly (Pictures and Words)” opens at the Barbican Center in London on Sept. 25.
CREDITS:
Software developed by Leif Ryge for Trevor Paglen Studio